狮威娱乐有限公司点击下图进入官网:

狮威娱乐有限公司点击下图进入活动:

狮威娱乐有限公司点击下图进入领取彩金:

摩斯国际|http://msgjlghn.weebly.com
铁杆国际|http://tggjdisu.weebly.com
老易发游戏平台|http://lyfyxptdbhn.weebly.com
瑞博娱乐|http://rbylslll.weebly.com
葡京美翁彩金18元|http://pjmwcjynbgf.weebly.com
亚虎娱乐官网|http://yhylgwwiqe.weebly.com
> 打印(gini_index([[[1],[1,0]],[[1],[1,0]]],[0,1]))打印(gini_index([[[1,0],[1,0]],[[1],[1]]],[0,1]))
运行代码,并将打印两个基尼系数,相应的第一个最糟糕的情况是1.0,第二个是在最好的情况下是0.0。
1.0
0.0
2.2创建一个分割点
一个点的数据集属性和一个阈值。
我们可以总结为一个给定的属性来确定一个阈值分割数据。这是一个有效的数据分类方法。
创建一个分割点包括三个步骤,第一步已经讨论了计算基尼系数的一部分。剩下的两个部分分别为:
1。分类数据集。
2。所有的评估(可行性)。
我们详细看每一步。
2.2。1分区数据集
意味着我们将数据集对于一个给定的数据集的属性(或者在列表下面的属性表)和相应的阈值,数据集被分为两个部分。
一旦数据被分为两个部分,我们可以用基尼系数来评估成本函数的积分。
分割需要遍历每一行的数据,数据集属性的值是适合每个数据点和阈值的大小的数据点的相应部分叉车(对应于树结构和右叉)。
下面是一个名叫test_split()函数,它可以实现功能:
#分割的数据集的属性和属性值
Def test_split(指数、价值、数据):
左、右=列表(),()
中的一行数据集:
如果行(指数) < value:
左。追加(行)
的其他的:
正确的。追加(行)
返回左和右
代码很简单。
注意,在代码中,属性值大于或等于阈值的数据点分为正确的组。
2.2。2评估所有分割点
gini_index基尼函数()和分类函数test_split()的帮助下我们可以开始评估分割过程。
对于一个给定的数据集,每个属性,我们必须检查所有可能的阈值作为候选分割点。然后,我们将根据成本(成本)来评估其划分点,最终选出最优分割点。
最优分割点被发现后,我们可以使用它作为一个决策树节点。
这是所谓的详尽的贪婪算法吗。
在本例中,我们将使用一个字典来表示节点的决策树,它可以按照存储数据变量的名字。在选择最优的点和使用它作为一个新的节点树,我们保存对应的下标的属性,对应值分割,根据数据分割后值分割的两个部分。
分割后每组数据是一个更小的数据集(可以继续操作),它实际上是原始数据集中数据根据分割点分配给左叉或右叉数据集。你可以想象我们如何进一步分割,每组数据周期直到构建决策树。
下面是一个名叫get_split()函数,它可以实现上面的步骤。你会发现,它遍历每个属性值)(除了相应的类别和属性值,它将在每一次迭代分割数据 现金牛牛,评估分割点。
当所有的检查完成后,最优分割将记录并返回。
#选择最佳分裂点数据集
Def get_split(数据):
Class_values =列表(集(行中的一行数据集[1]))
B_index,b_value b_score b_groups = 999、999、999年,没有
该指数的范围(len(数据集[0])- 1):
中的一行数据集:
组= test_split(指数、行(指数)、数据集)
class_values基尼= gini_index(集团)
如果基尼 < b_score:
B_index,b_value b_score b_groups =指数、行(指数),基尼、组
返回{”指数:b_index,“价值”:b_value,“团体”:b_groups }
我们可以在一个小合成数据集测试这个函数以及整个数据集分割过程。
的的的的的(X1,X2)Y
2.771244718 1.784783929 0
1.728571309 1.169761413 0
3.678319846 2.81281357 0
3.961043357 2.61995032 0
2.999208922 2.209014212 0
7.497545867 3.162953546 1
9.00220326 3.339047188 1
7.444542326 0.476683375 1
10.12493903 3.234550982 1
6.642287351 3.319983761 1
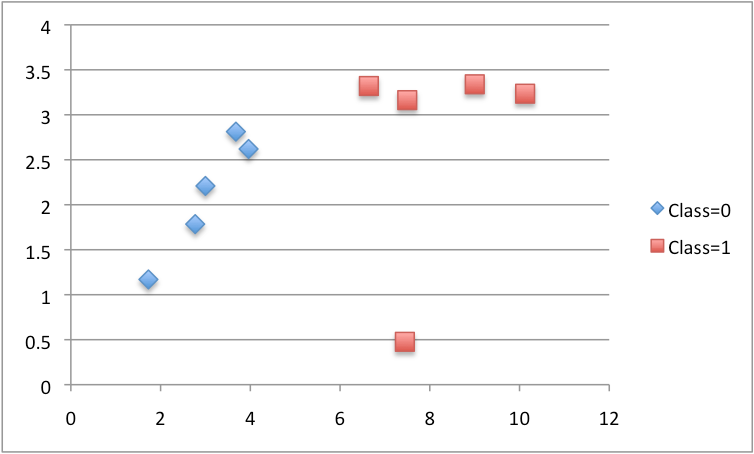
与此同时,我们可以用不同的颜色标记不同的类,数据集。图中显示,我们可以从X1轴(我。e。图中,X轴)选择一个值将数据集。
样品的所有代码集成如下:
#分割的数据集的属性和属性值
Def test_split(指数、价值、数据):
左、右=列表(),()
中的一行数据集:
如果行(指数) < value:
左。追加(行)
其他:
正确的。追加(行)
返回左和右
#计算基尼系数划分数据集
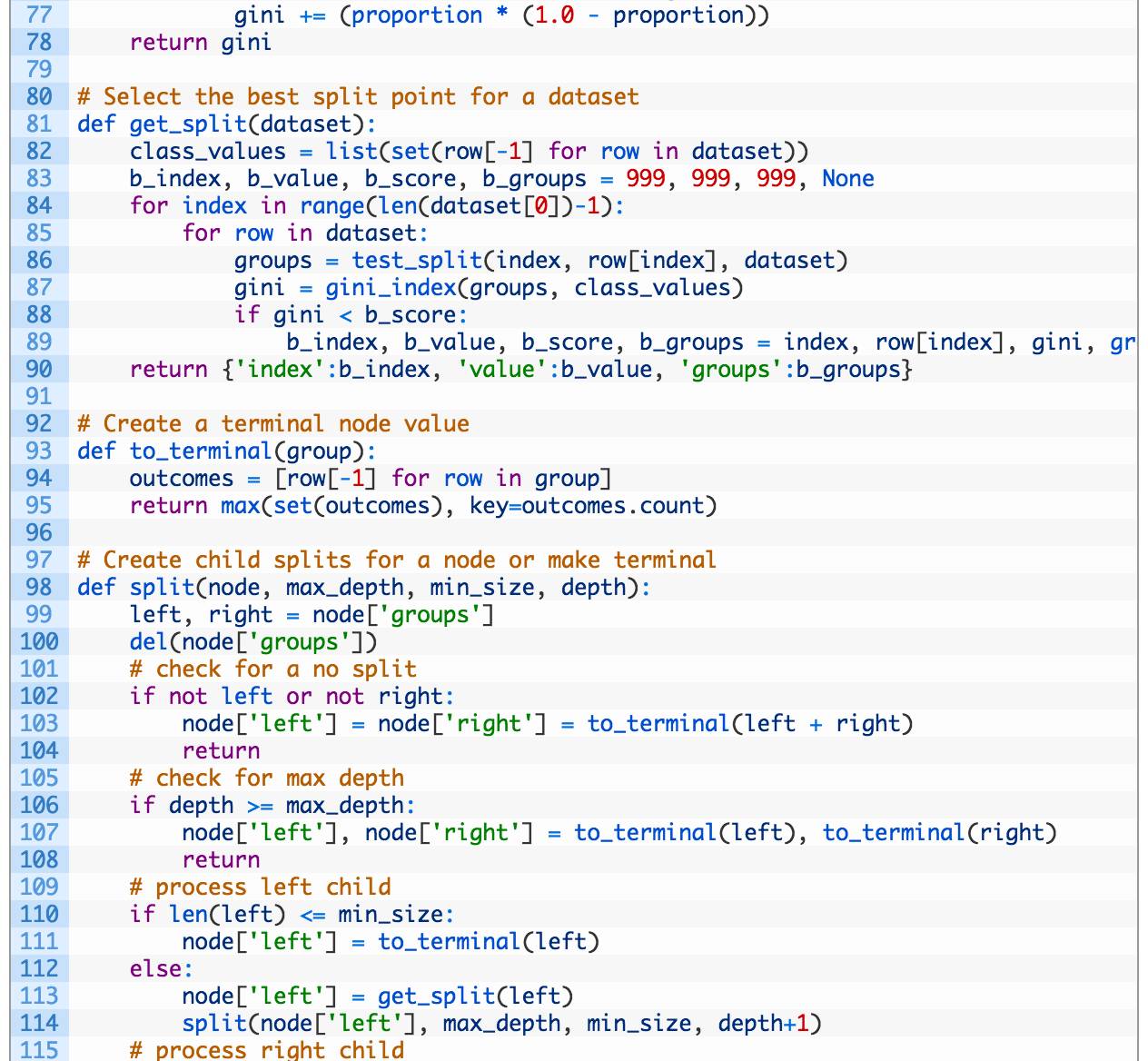
Def gini_index(团体、class_values):
基尼= 0.0
对于class_value class_values:
组的组:
大小= len(集团)
如果尺寸= = 0:
继续
比例=[[1]的行组中)。计数(class_value)/浮动(大小)
基尼+ =(比例*(1.0 -比例)
返回基尼
#选择最佳分裂点数据集
Def get_split(数据):
Class_values =列表(集(行中的一行数据集[1]))
B_index,b_value b_score b_groups = 999、999、999年,没有
该指数的范围(len(数据集[0])- 1):
中的一行数据集:
组= test_split(指数、行(指数)、数据集)
class_values基尼= gini_index(集团)
打印(“X % d < %。3f Gini=%。3f‘ % ((index+1), row[index], gini))
如果基尼 < b_score:
B_index,b_value b_score b_groups =指数、行(指数),基尼、组
返回{”指数:b_index,“价值”:b_value,“团体”:b_groups }
数据集=[[2.771244718,1.784783929,0]。
[1.728571309,1.169761413,0]。
[3.678319846,。81281357,0]。
[3.961043357,。61995032,0]。
[2.999208922,。209014212,0]。
[7.497545867,3.162953546,1],
[9.00220326,3.339047188,1],
[7.444542326,0.476683375,1],
[10.12493903,3.234550982,1],
[6.642287351,3.319983761,1]]
分= get_split(数据集)
打印(’分裂:[X % d < %。3f]‘ % ((split[’index‘]+1), split[’value‘]))
优化get_split()函数可以输出每个点及其对应的基尼系数。
运行上面的代码后,将打印所有的基尼系数和选择最优点。在这个例子中,它选择了X1<6.642 作为最终完美分割点(它对应的基尼系数为 0)。
X1 < 2.771 Gini=0.494
X1 < 1.729 Gini=0.500
X1 < 3.678 Gini=0.408
X1 < 3.961 Gini=0.278
X1 < 2.999 Gini=0.469
X1 < 7.498 Gini=0.408
X1 < 9.002 Gini=0.469
X1 < 7.445 Gini=0.278
X1 < 10.125 Gini=0.494
X1 < 6.642 Gini=0.000
X2 < 1.785 Gini=1.000
X2 < 1.170 Gini=0.494
X2 < 2.813 Gini=0.640
X2 < 2.620 Gini=0.819
X2 < 2.209 Gini=0.934
X2 < 3.163 Gini=0.278
X2 < 3.339 Gini=0.494
X2 < 0.477 Gini=0.500
X2 < 3.235 Gini=0.408
X2 < 3.320 Gini=0.469
分割(X1。 < 6.642]
因为我们现在已经能够找到的数据集,最优分割点,我们现在看看我们可以使用它来构建决策树。
2.3生成树模型
创建一个根节点的树(根节点)是更方便,可以叫get_split()函数和扩散到整个数据集可以达到这个目的。但是更多的节点添加到树更有趣。
建立一个树结构主要分为三个步骤:
1。创建一个终端节点
2。递归分割
3。整棵树的建设
2.3。1创建一个终端节点
我们需要决定何时停止树的“增长”。
我们可以控制在两个条件:树的深度和数据点的数量在每个节点分裂。
树的深度:这代表了一个树从根节点的节点数量的上限。一旦达到树节点树中的上界,该算法将停止数据分割,添加新的节点。上帝会更复杂,更可能是合适的训练集。
最小的节点数量:这是一个节点分裂后部分数据点的个数的最小值。一旦达到或者低于最小值,那么该算法将停止数据分割,添加新的节点。数据集分为只有少数节点的数据点划分两部分被认为是太尖,并有可能适应训练集。
这两个方法根据用户给定的参数,参与建设的树模型的过程。
此外,有一个情况。算法是可能选择一个部门,分割后的数据分为同一组的所有数据(这是右或左叉叉只有一个分支数据,另一个分支)。在这种情况下,因为没有数据到另一个分支的树,我们不能继续我们的工作添加节点分割。
基于上述内容,我们已经有一些停止树判别机制的“增长”。当一个节点树中停止增长,节点称为终端节点,用来进行最终的预测。
预测是一个过程,通过选择属性值。当遍历树到最后一个节点在一个数据集分割算法将选择一组最常见的值作为预测价值。
下面是一个名叫to_terminal()函数,每一组的收据可以选择一个值表示。他可以返回一系列的数据点是最常见的值。
#创建一个终端节点的值
Def to_terminal(集团):
结果=[[1]的行组中)
马克斯的回归(设置(结果),键=结果。计数)
2.3。2递归分区
了解如何以及何时创建终端节点后,我们现在可以开始建立树模型。
建立树模型,我们需要对于一个给定的数据集称为重复如上定义get_split()函数,不断创建树中的节点。
在现有的节点加入新节点称为子节点。任何节点的树,它可能没有子节点(节点和终端节点),一个子节点(节点可以直接预测)或两个子节点。在程序中,在一个节点在字典里,我们将两个子节点的树叫左和右。
一旦创建一个节点,我们可以递归地分裂成两个子节点的数据集,调用相同的函数,除以子数据集,并创建一个新节点。
下面是一个函数的递归的实现过程。它的输入参数包括:一个节点(节点),树的深度(max_depth),最小数量(min_size)和当前树节点深度(深度)。
显然,当运行这个函数一开始,根节点将被传递,当前的深度为1。函数的功能分为以下步骤:
1。首先,两半提取节点分割数据的使用,与此同时,数据将被删除的节点(前逐渐分工,节点不需要使用相应的数据)。
2。然后,我们将检查左和右叉叉的节点数据集是空的。如果是这样,那么它将创建一个终端节点。
3。与此同时,我们将检查是否达到最大深度。如果是这样,那么它将创建一个终端节点。
4。然后,我们将进一步操作到左子节点。如果小于阈值,该组织将创建一个数据终端节点和停止进一步的操作。否则它将创建和添加形式的深度优先节点,直到底部的分叉。
5。向右子节点相同的操作,继续增加直到你到达终端节点。

2.3。3建设整棵树
我们都将在一起。
创建一个根节点的树包括创建和递归地调用split()函数来构建整棵树不断细分的数据。
下面是实现的功能bulid_tree()函数是一个简化版本。
#构建决策树
Def build_tree(火车,max_depth min_size):
根= get_split(数据集)
split(根,max_depth min_size,1)
返回root
我们可以在合成数据集测试整个过程如上所述。以下是完整的。
其中还包括一个print_tree()函数,它可以递归地打印出一个决策树节点。后打印不清晰的树状结构,但它可以给我们一个总体印象树结构,并且可以帮助决策。
#分割的数据集的属性和属性值
Def test_split(指数、价值、数据):
左、右=列表(),()
中的一行数据集:
如果行(指数) < value:
左。追加(行)
其他:
正确的。追加(行)
返回左和右
#计算基尼系数划分数据集
Def gini_index(团体、class_values):
基尼= 0.0
对于class_value class_values:
组的组:
大小= len(集团)
如果尺寸= = 0:
继续
比例=[[1]的行组中)。计数(class_value)/浮动(大小)
基尼+ =(比例*(1.0 -比例)
返回基尼
#选择最佳分裂点数据集
Def get_split(数据):
Class_values =列表(集(行中的一行数据集[1]))
B_index,b_value b_score b_groups = 999、999、999年,没有
该指数的范围(len(数据集[0])- 1):
中的一行数据集:
组= test_split(指数、行(指数)、数据集)
class_values基尼= gini_index(集团)
如果基尼 < b_score:
B_index,b_value b_score b_groups =指数、行(指数),基尼、组
返回{”指数:b_index,“价值”:b_value,“团体”:b_groups }
#创建一个终端节点的值
Def to_terminal(集团):
结果=[[1]的行组中)
马克斯的回归(设置(结果),键=结果。数)
#创建子节点的分裂或者使终端
Def分裂(节点,max_depth min_size,深度):
左、右=节点(“集团”)
德尔(节点(“集团”))
#检查没有分裂
如果不左不右:
节点的节点[’左‘]=[’正确‘]= to_terminal(左+右)
返回
#检查最大深度
如果> = max_depth深度:
节点(“左”),节点=[’正确‘]to_terminal(左),to_terminal(右)
return
#过程左子
如果len(左) <=min_size:
节点[’左‘]= to_terminal(左)
其他:
节点[’左‘]= get_split(左)
split(节点(“左”)、max_depth min_size,深度+ 1)
#过程对孩子
如果len(右) <=min_size:
节点[’正确‘]= to_terminal(右)
其他:
节点[’正确‘]= get_split(右)
split(节点(“正确的”)、max_depth min_size,深度+ 1)
#构建决策树
Def build_tree(火车,max_depth min_size):
根= get_split(数据集)
split(根,max_depth min_size,1)
返回根
#输出一个决策树
Def print_tree(节点深度= 0):
云顶线上娱乐如果isinstance(节点,dict类型):
打印(“[X % d % s < %。3f]’ % ((depth*‘ ’, (node[‘index’]+1), node[‘value’])))
Print_tree(节点“左”,深度+ 1)
Print_tree(节点“正确”的,深度+ 1)
其他:
(% s)打印(‘ % s ’ %((*的深度,节点)))
数据集=[[2.771244718,1.784783929,0]。
[1.728571309,1.169761413,0]。
[3.678319846,。81281357,0]。
[3.961043357,。61995032,0]。
[2.999208922,。209014212,0]。
[7.497545867,3.162953546,1],
[9.00220326,3.339047188,1],
[7.444542326,0.476683375,1],
[10.12493903,3.234550982,1],
[6.642287351,3.319983761,1]]
树= build_tree(数据集,1,1)
Print_tree(树)
在操作的过程中,我们可以修改树的最大深度,并观察其效果在打印这棵树。
当1(我的最大深度。e。,叫build_tree()函数的第二个参数),我们可以发现这棵树使用之前我们发现完美的点(唯一的分割点树)。这棵树只有一个节点,也称为决策树桩。
(X1 < 6.642]
[0]
[1]
添加到最大深度2时,我们被迫失去算法不需要分离力条件下的分割。因此,左和右叉上的X1属性被使用两次分裂已经完美的积分数据。
(X1 < 6.642]
(X1 < 2.771]
[0]
[0]
(X1 < 7.498]
[1]
[1]
最后,我们可以试着最大深度为3:
(X1 < 6.642]
(X1 < 2.771]
[0]
(X1 < 2.771]
[0]
[0]
(X1 < 7.498]
(X1 < 7.445]
[1]
[1]
(X1 < 7.498]
[1]
[1]
这些测试表明 乐虎国际 ,我们可以优化代码,以避免不必要的部门。参见扩展了相关内容。
现在我们已经可以(完整的)创建一个决策树,让我们看看如何使用它对新数据进行预测。
2.4使用模型预测
使用决策树模型作出决定,我们需要根据给定的数据遍历整个决策树。
像之前一样,我们仍然需要使用递归函数实现的过程。本文提出基于数据的特定点,相同的影响预测规则应用于左子节点或子节点。
我们需要检查一个子节点,是否可以作为预测结果返回的终端节点,或他是否分裂节点包含下一层需要考虑。
以下是实现上述过程称为预测()函数,你可以看到它是如何处理该指数与数字给定节点。

然后,我们使用合成数据集测试函数。下面是硬编码只使用一个节点树(即决策树树桩)病例。为每个数据的数据集。
运行示例,它将按照打印出每个数据预期的预测结果。
预期= 0,= 0
预期= 0,= 0
预期= 0,= 0
预期= 0,= 0
预期= 0,= 0
预期= 1 = 1
预期= 1 = 1
预期= 1 = 1
预期= 1 = 1
预期= 1 = 1
现在,我们不仅掌握了如何创建一个决策树,但也知道如何用它来预测。让我们试试这个算法在实际的数据集。
2。案例研究5法案的数据集
本节描述在金钱数据集使用购物车算法过程。
第一步是导入数据,将加载的数据转换为数字形式,使我们能够用它来计算分割点。,我们使用辅助函数load_csv()加载数据和str_column_to_float()来将字符串数据转换为浮点数。
我们将使用5折交叉验证方法(5 -折交叉验证)对算法的性能进行评估。这意味着,一条记录,1273/5 = 274。四、270年的数据点。Evaluate_algorithm我们将使用辅助函数()来评估算法的性能与accuracy_metric交叉验证组()来计算预测精度。
完成的代码如下:




参数的使用包括:max_depth 5、min_size 10。一些实现之后,我们决定使用购物车的参数算法,但这并不意味着使用参数是最优的。
运行情况下,它会打印出每个部分的数据,平均分类精度和数据的所有部分的平均表现。
从数据可以看出,购物车的分类算法,选择设置,达到约83%的平均分类精度。它的性能比零规则算法只有50%正确的规则算法(零)。
成绩:[83.57664233576642,84.30656934306569,85.76642335766424,81.38686131386861,81.75182481751825)
意思是精度:83.358%
第三,扩展
本节列出了扩展项目这一节中,你可以根据这个来探索。
1。调优参数算法(算法调优):使用购物车算法在金钱数据集不是可调参数。你可以尝试不同的参数值,以获得更好的和更好的结果。
2。交叉熵、交叉熵):另一个用来评估成本函数是一个函数的划分点交叉熵(对数损失)。你可以尝试使用成本函数作为替代。
3。修剪修剪(树):另一个训练的过程中减少拟合程度是修剪的重要途径。你可以学习和尝试实现一些修剪方法。
4。数据集的分类(分类数据集):在上面的例子中,这棵树模型旨在解决数字或序列数据。你可以试着修改树模型(重大变化的属性,方程的形式而不是那种),处理的数据类型。
5。回归问题(回归):可以通过使用不同的成本函数和不同的方法来创建一个终端节点,使模型可以解决问题。
6。更多的数据集:你可以试着使用这个算法在UCI机器学习库的其他数据集。
原:http://machinelearningmastery。Com/implement -决策树算法——python /
?本文编制的核心机,请联系这对公众授权转载。
?- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
加入的核心机(全职/实习记者):人力资源@ jiqizhixin。com
提交或寻求报告:@ jiqizhixin编辑。com
广告和商务合作:@ jiqizhixin bd。com
(原标题:教练受伤学生前者是喝醉酒的麻烦)
 李先生发现疑似救命棒kai“教训”。
李先生发现疑似救命棒kai“教训”。
广州天河东方莫斯科,主任傅云母muscovitum游泳俱乐部承诺,他将改善我们的教学方法
在游泳俱乐部参加训练,但是训练在陆地上应该当教练与“铁”,左肘击后导致肘关节软组织挫伤。在广州天河东方莫斯科,云母muscovitum傅游泳俱乐部这次相遇,几天后仍然恐慌凯(化名)12岁。
2月8日,涉及张Jiaolian解释,我喝醉了,请同事替代,但做了一个拯救生命的坚持在打那个顽皮的小凯。凯和他的家人,造成的损坏张Jiaolian深感抱歉和俱乐部,并承诺改善教学方法。
新快报》记者朱陈烁实习生Kejun总结/摄影
陆地训练的教练一根棍子手肘
莫斯科、云母muscovitum傅游泳俱乐部位于广州天河体育馆游泳的华南师范大学的附属中学,小学六年级kai是旧的一个学生。锻炼身体,凯3岁以来一直在这里游泳、学习和培训课程有四到五次一个星期平
